Speech signal processing
Automatic speech recognition
Automatic speech recognition(ASR) is the task of taking an speech utterance as an input and converting it into a text. ASR is a core technique of human-machine interface system. Application of ASR is interface of smart home, phone, and so on. ASR can be categorized into two fields.
- Acoustic modelling
- Feature compensation
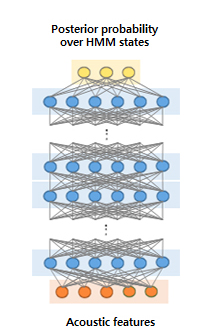
Acoustic modelling
In automatic speech recognition, an acoustic model is trained in order to represent the characteristic behavior of the speech signal. Conventionally, the Gaussian mixture model (GMM) was widely used for acoustic modelling, but the deep neural network (DNN) is being actively researched nowadays due to its outstanding performance in ASR.
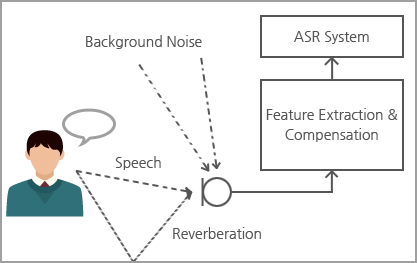
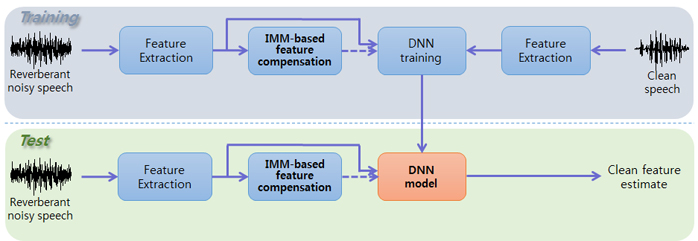
Feature compensation
In automatic speech recognition, the received signals are often distorted by various interferences, which lead to performance degradation. In order to alleviate the performance deterioration in adverse environments, the distortion in the speech feature can be reduced via feature compensation techniques.
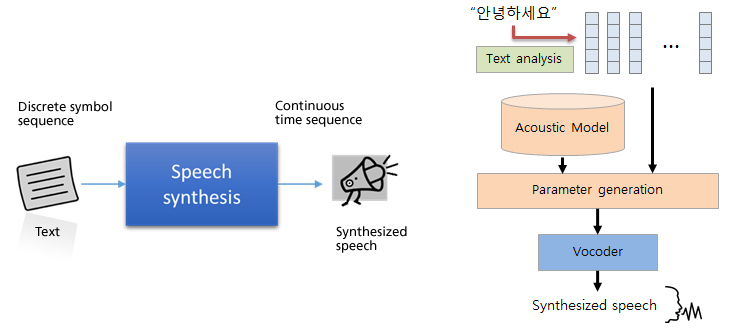
Speech synthesis
Speech synthesis is a technique of synthesizing a given text input into speech.
Speech synthesis is actively used in various fields to convey information to the users through speech from machines such as smartphone interface, personal assistant in a vehicle, ARS, robot interface, etc..
Research area of speech synthesis can be divided into 2 major areas:
- High quality speech synthesis
- Speaker adaptive speech synthesis
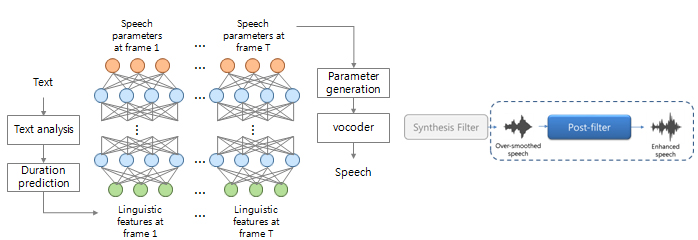
High quality speech synthesis
Conventional speech synthesis generates machine-like voice with distinctive timbre and accent. High quality speech synthesis aims to synthesize speech with naturalness and intelligibility similar to humans.
The following methods can be employed for high quality speech synthesis:
- High quality vocoder
- Improving acoustic models
- Post processing
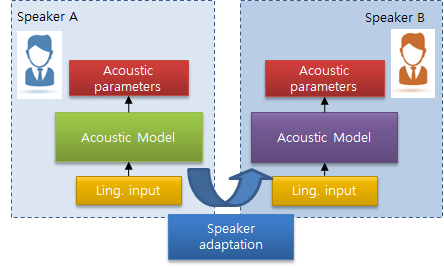
Speaker adaptive speech synthesis
A vast amount of data is required in order to build the speech synthesis system of a single speaker. Because this process in costly and time consuming, speaker adaptive speech synthesis is necessary in order to build speech synthesis system with a small amount of data.
The training process of speaker adaptive speech is not limited to speaker adaptive training, but can also perform adaptive training by altering speaking style such as:
- Speaker adaptation to target speaker
- Emotional TTS
- singing voice TTS
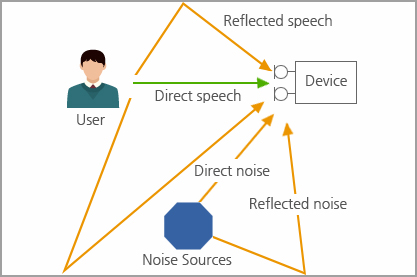
Speech enhancement
Speech enhancement improves the degraded speech intelligibility and quality by using audio signal processing techniques and algorithms. Speech enhancement plays an important role in post-processing of audio signal processing area. Application of speech enhancement is mobile and telecommunication systems, hearing aids, ASR, and so on. Speech enhancement can be categorized into three fields.
- Noise reduction
- Echo cancelation / Dereverberation
- Speech intelligibility
- Room
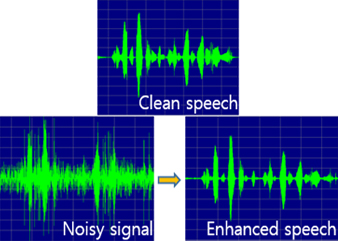
Noise reduction
While recording the speech signal using microphone, the noise signal which makes the quality degraded is also recorded. Noise reduction aims to remove the noise signal without speech distortion.
- Single channel enhancement
- Multi channel enhancement
Echo cancellation / Dereverberation
Acoustic echo cancellation (AEC) or suppression (AES) is a technique to reduce the echo originated from acoustic coupling between loudspeakers and microphones. To improve the performance of AEC and AES, stereophonic acoustic echo suppression (SAES) and residual echo suppression techniques are required for various applications.
- Multichannel echo cancellation / Dereverberation
- Residual echo suppression
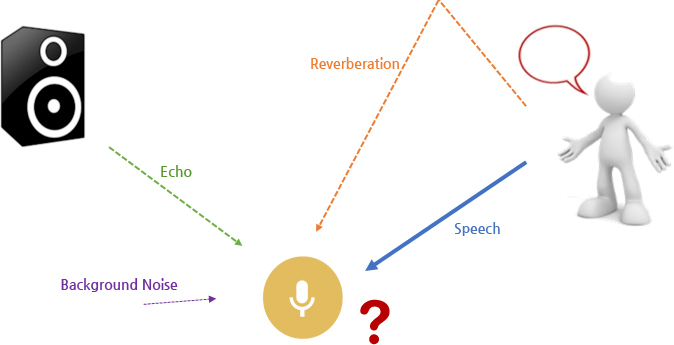
Speech intelligibility enhancement
Speech intelligibility is a measure of how comprehensible speech is in given conditions. Compared with the noise reduction techniques, speech intelligibility area aims to improve speech quality focusing on converting the speech signal in terms of the intelligibility.
- Filtering technique
- Band width extension
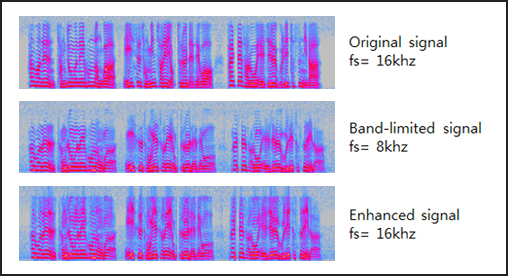
Speech coding
Speech coding is an application of data compression of digital audio signals containing speech. The purpose of speech compression is to reduce the number of bits required to represent speech signals in order to minimize the requirement for transmission bandwidth or to reduce the storage costs.
- Source coding(data compression)- High efficiency audio coding
- Channel coding(error correction)- Error robust audio coding


Room 415 INMC (bldg. 132), Seoul National University, 1 Gwanak-ro (San 56-1, Sillim-dong), Gwanak-gu, Seoul, Korea, 08826
Tel : +82-2-880-8439, +82-2-884-1824
COPYRIGHT©휴먼인터페이스 ALL RIGHT RESERVED